2.1.7 Triggering the Scale Event
Scaling can be uncontrolled, controlled, or controlled with hysteresis.
2.1.7.1. Uncontrolled Scaling
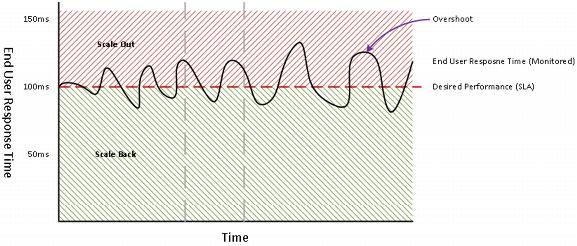
When triggering a scale event, you cannot determine whether to increase capacity when the threshold exceeds or falls below the set point. This causes a ping-pong effect, where the infrastructure is constantly scaling out and scaling back as it seeks the set point for the triggering metric. Depending on the instability of the system, this can result in significant overshoot while seeking the set point, where the system goes back and forth between increasingly over-provisioning resources and then decreasing them, resulting in an ever-increasing problem. The following figure illustrates uncontrolled scaling.
Figure 6. Uncontrolled Scaling
This constant expansion and contraction of resources with today’s technology places an undesirable load on the infrastructure and can ultimately result in further degradation of the service.
2.1.7.2. Controlled Scaling
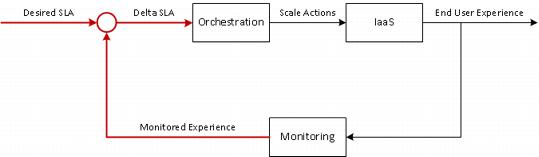
The scaling process must be controlled to provide the overall stability of the application and its underlying infrastructure.
Figure 7. Scaling Controller
The monitoring information, in conjunction with the preferred performance of the system (set point), must be controlled by the overall system to prevent the constant seeking of the set point. This allows the infrastructure to operate more efficiently and in a far more stable manner. The simplest control scheme for dynamic IaaS is to add hysteresis to the system.
Figure 8. Controlled Scaling Using Hysteresis
With this method of control, instead of aggressively seeking the set point for the end-user experience, a band can be created around it. Action is taken only when the performance falls outside of this band.
In the preceding example, as end-user experience improves in the form of decreased response time, a higher than necessary service is provided and too much capacity is consumed. This results in spending too much on the service and a scaling back of resources to get as close as possible to the SLA (set point). When response time increases and there is a reduction in service quality, when the SLA the SLA scale out threshold is reached, resources are added to bring the service level to the set point.
You can bring the service level slightly above or below the preferred set point based on your understanding of the service, how it responds to additional resources, and the cause of the increase.
By creating a dead band within the scaling model, service performance is allowed to fluctuate around the set point and not aggressively seek it, which can result in the ping-pong effect.